Learned Image and Video Coding
Ying Liu, Computer Science and Engineering
Video cameras are proliferating at an astonishing rate in recent years. It is predicted that the number of cameras the world will see in 2030 is approximately 13 billion. The huge amount of visual data can be leveraged in a wide range of existing and future applications ranging from video streaming, mobile video sharing, surveillance camera and autonomous vehicles. Recent advances in deep learning have achieved great success in computer vision tasks. The Video and Image Processing (VIP) Lab focuses on deep learning-based image and video coding, video prediction and generation, as well as other visual recognition tasks. The tools used involve, but are not limited to: convolutional neural network (CNN), generative adversarial network (GAN), recurrent neural networks (RNN), and transformers.
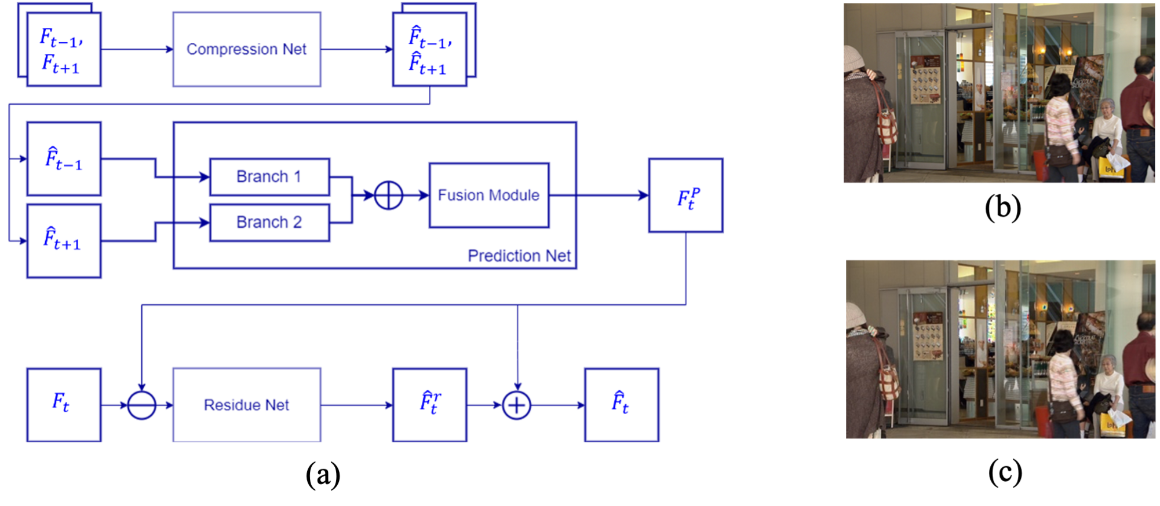
Figure 1. (a) The architecture of the proposed motion-aware deep video coding network; (b) ground-truth frame ; and (c) decoded frame.
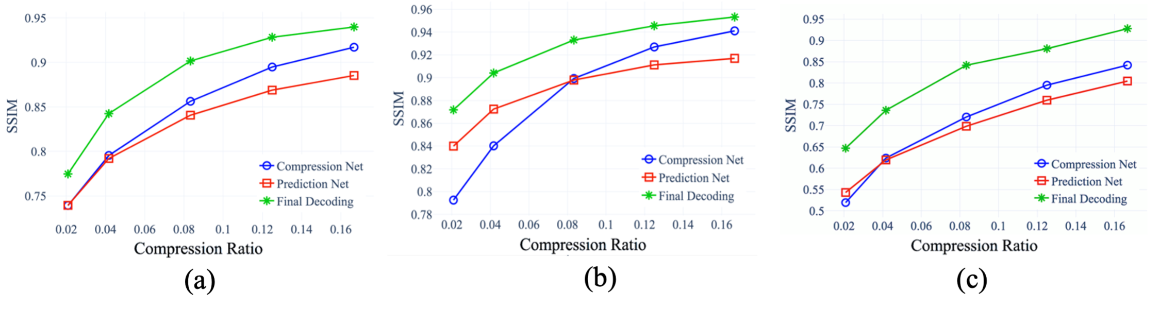
Figure 2: The SSIM versus compression ratios for (a) the BQ Mall video sequence; (b) the Basketball Drill video sequence; and (c) the Party Scene video sequence.
Students in the VIP lab use the WAVE facilities to develop deep learning algorithms and train deep models on large-scale datasets. The VIP lab has successfully obtained fundings from the National Science Foundation, and the School of Engineering at Santa Clara University.
More details can be found at The Video and Image Processing (VIP) Lab.