How Must Journalists and Journalism View Generative AI?

Science Photo Library/Canva for Education
Subramaniam Vincent (@subbuvincent) is the director of journalism & media ethics at the Markkula Center for Applied Ethics at Santa Clara University. Views are his own.
How might journalists–reporters, illustrators, podcasters, broadcasts, editors, data journalists, investigators, and documentary filmmakers–view generative AI? This is a complex topic that touches on many aspects. A brief article cannot be comprehensive on all of the complexities lurking behind this question. I’m going to focus on the question of whether the news media industry should use Generative AI for journalistic writing. Journalists use tools all the time for their work, so the means and ends lens may be a practical way to sort through the ethical questions.
Let’s start with ‘ends’
By “ends,” I mean efficiency for journalistic writing. Let’s say we were not concerned with how ethical generative AI is as a technological means to use for journalism writing. We simply said, it’s already here, it’s a competitive marketplace, and there’s always economic pressure. Let’s just use it for journalistic news writing. Here are the considerations.
- Journalists, at least normatively, engage in truth determination as a key function. The everyday practice of reporting the news is rooted in the journalistic agency of covering reality. Journalistic writing is a specific type of writing–its north star is the truth, as elusive as that becomes.
- (Of course, there are massive failings in journalism–truthful narratives do not always emerge as selective subordination of voices, people, facts, and stories have a long-running history in hegemonic journalistic practice.)
- But fundamentally, the professional and the practice can, at least in principle, be questioned around truthfulness as a standard.
Now let’s look at the case of using ChatGPT to write.
Truth and generative AI
Truth is not the goal. OpenAI is open enough to say that there is no source of truth in ChatGPT. See their limitations section.
“ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers. Fixing this issue is challenging, as: (1) during RL training, there’s currently no source of truth; (2) training the model to be more cautious causes it to decline questions that it can answer correctly; and (3) supervised training misleads the model because the ideal answer depends on what the model knows, rather than what the human demonstrator knows.”
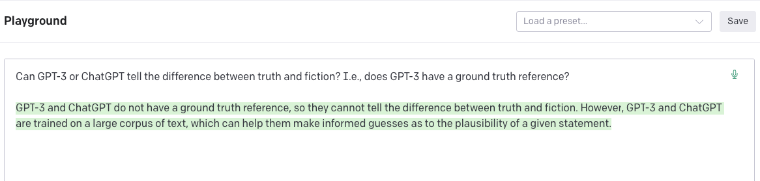
Go further. Ask OpenAI’s playground itself on whether the machine can tell the difference between truth and fiction:
“GPT-3 and ChatGPT do not have a ground truth reference, so they cannot tell the difference between truth and fiction. However, GPT-3 and ChatGPT are trained on a large corpus of text, which can help them make informed guesses about the plausibility of a given statement.”
It’s in the design. ChatGPT (or competitors who also use large language models or LLMs) is not designed to operate anchored to the word “truth” in a realistic or even discursive sense of the term. To be clear, what is ChatGPT for? In small font, at the bottom of the ChatGPT page, you’ll see this:
“Our goal is to make AI systems more natural and safe to interact with.”
There is a date-cut off. If you push ChatGPT hard enough about current developments, it will repeat one line back to you–that its training cut-off date is 2021. Try asking ChatGPT, “Did Kari Lake win in Arizona” and you’ll see what I mean. Since that election happened in 2022, ChatGPT does not “know” about it. No training data.
So even from a strictly exploitative and extractive ends perspective, ChatGPT is not for journalistic writing.
Trusting generative AI for stories
Enough trust discussions already. I’ve written before that the trust problem in mainline journalism is more complicated than the elite narrative has made it out to be. See these two pieces for more: (Values, not trust, and What Is Our Brain Doing When We Click News Articles?)
Someone tested generative AI news headlines with people. Foretelling how the public at large may treat generative AI news writing was some research that came out in mid-2022, about six months before OpenAI released ChatGPT. In their work studying how people will perceive news generated by AI, a group of researchers (Chiara Longoni, Audrey Fradkin, Luca Cian, and Gordon Pennycook) pointed out that if it is disclosed that a headline was AI-generated (a form of labeling), they find that readers attach an additional credibility deficit to the news. See: News from Generative Artificial Intelligence Is Believed Less.
Generative AI is no magic bullet. If journalists start using generative AI for news writing, the so-called trust deficit may get another wheel to accelerate on.
Will AI labels/transparency work? Doesn’t transparency demand that news organizations using machines to write stories should disclose that to users? This finding only brings up a tension between the risk of labeling and the assumptions of the reader. It may only further drive publishers to be resistant to label AI-generated news text as such.
Binary disclosure won’t cut it. The real question for news readers and publishers is not plain disclosure in a binary sense: Written by human vs. written by generative AI. Transparency has to be along AI-literacy lines among the public, beyond simplistic labels. We may need a deep transparency of models, training data corpora, and model limitations to the reader, in plain de-complexed language. That is a hard ask.
The ‘means’ question with Generative AI
‘Means’ matter for ethical journalism. The deep transparency question is a serious one. Like, how does generative AI work and what does it have to do with how journalism is put together? Here, things get even more ethically complicated.
AI opacity means sourcing is a deadend. ChatGPT does not cite all its sources when it generates text. This is how its (large language) models work. For journalists, sources, and sourcing always matter. OpenAI has not posted a list of all their training sources for ChatGPT. There are some guesses floating around. So why trust a talking tool that is opaque?
Appropriating the open web. Further, there are substantive ethical questions about crawling the open web and using the creative expression of humanity (even if all the text was uncopyrighted) this way for generative machines. It’s one thing for the collective commons to be open to humanity. It’s another thing for it to be used for massive computational pattern-matching models to get machines to blindly mimic humanity. And it comes as no surprise, for example, when Getty Images sued Stability AI (image generative AI) for copyright infringement in London.
In this interview published by the Tech Policy Press on an indigenous perspective on generative AI, Michael Running Wolf (North Cheyenne man, computer science PhD student, and former Amazon engineer) says this:
“It’s a lie to say that it only costs electricity to generate the art. That’s a lie. These Stable Diffusion could not do this if they didn’t have the ability to scan the intellectual property of the internet. And that is worth something.”
Compare generative AI to a child learning language in the open world. Training a machine is not the same as ChatGPT going from kindergarten to college in a city and coming out like a grown-up with communicative abilities. For journalism, the “means” question then is this: How a generative AI’s training data corpora were put together and the extractive norms that went into it–must matter to whether you might consider using it for any inputs to a story.
Risks. There is the risk of perpetuating cultural appropriation and unremunerated creativity through everyday media work. There’s already the admitted risk of human culture’s historical and current power biases around people, social groups, gender, and roles that will simply show up in the text. How much will an editor be able to catch? There are ethical questions about Large Language Models upstream of journalism that are unresolved and currently in serious debate.
Two great interviews on the generative AI hype for journalists.
One area of Generative AI that has potential for journalism is summarization
Why is summarization a useful intervention area? On many occasions, breaking news and enterprise reporters are criticized for not including enough context in a story. Context can come in the form of summarizing the past on the same issue, or a key question on a development, or writing up a chronology, etc.
Enter search engine summarizer combos. There are some new search engine companies emerging that combine the convenience of conversational-AI with the traditional model of search engine results ranked by some measure of authoritativeness, reputation, relevance to queries, etc. Try this on the search engine Neeva.com:
“BLM response to Tyre Nichols murder by police.”
See the screenshot below. (Note, you will need an account for the generated AI summary above the search results).
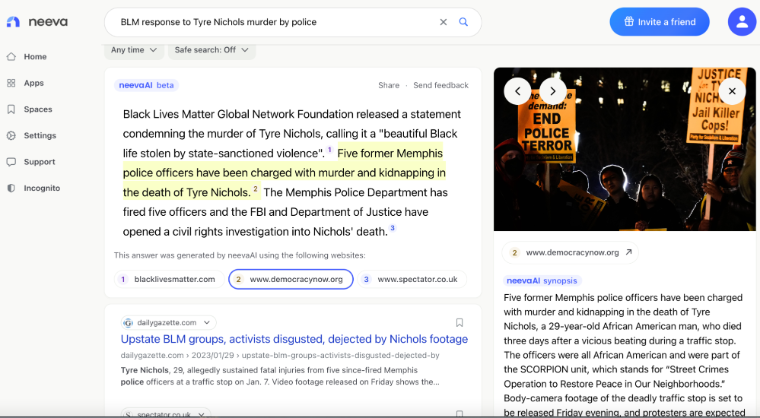
Summarizers with citations are intriguing. On the face of it, Neeva claims to be generating their summary responses to queries using the citations they link to below the summary. It is helpful to know which citations were used by the machine to produce this summary.
How does that help journalism? If a journalist were looking to quickly come up to speed on various aspects of an issue that was receiving wide coverage, she could check the cited links to learn more and then review the summary.
Cheap context generation. So it may seem that there is a case for search engines with a conversational interface being used as a source of cheap context generation (means) that reporters can insert into story sidebars (ends). And reporters can insert these with full credit to the search engine and the upstream citations.
Still, no wishing away the ethics of LLMs yet. Neeva also notes it uses LLMs, so all of the AI ethics questions about LLMs upstream of journalistic use still exist.
But from an “ends”-only standpoint, one distinction, however, is that search engines in principle can be held to an expectation that they do not serve fiction in their results when queried about current affairs, and hence their summarization ought to be held to those basic standards. ChatGPT on the other hand is open about not being able to distinguish between fact and fiction, a distinction in design.
In conclusion, should the news media industry use generative AI for journalistic writing? The short answer: No. There is too much ethical debt these systems are creating upstream before the tools even reach journalists. You may have editors review the generated text for facts and accuracy, but regressive biases in categorization and characterizations will be harder to catch. If you are summarizing historical contexts into a piece, and want to try machine summarizers, run them on selected articles and documents you yourself have vetted first. Proceed with caution.